Что такое JBIG и MHEG?
Что такое JBIG и MHEG?
JBIG предназначен для сжатия двоичных изображений (факсов,...), а MHEG - для мультимедиа-данных - интеграция неподвижных изображений, видео, аудио, текста и т.д.
Что такое MPEG?
Что такое MPEG?
MPEG - это группа людей в ISO (Internation Standards Organization), которые встречаются для выработки стандартов сжатия цифрового видео и аудио. В частности, они определили сжатый поток и декомпрессор для него. Алгоритмы сжатия определяются индивидуально каждым производителем, в чем и достигается преимущество в рамках опубликованного международного стандарта. Группа MPEG собирается приблизительно четыре раза в год примерно на неделю. Основная работа делается между встречами, будучи организованной и спланированной на них.
Где взять исходные тексты программ?
Где взять исходные тексты программ?
Существует несколько бесплатно распространяемых архивов, служащих основой всех коммерческих пакетов. Наибольшего интереса заслуживает работа под руководством Chad Fogg. Это реализация схемы для MPEG 2 с поддержкой MPEG 1, которая является хорошей отправной точкой для создания собственного кодера и изучения практической части как MPEG 2, так и MPEG 1.
это предсказывать движение от кадра
Иллюстрация 3

Основная идея всей схемы - это предсказывать движение от кадра к кадру, а затем применить дискретное косинусное преобразование (ДКП), чтобы перераспределить избыточность в пространсве. ДКП выполняется на блочках 8х8 точек, предсказание движения выполняется на канале интенсивности (Y) на блоках 16х16 точек, или, в зависимости от характеристик исходной последовательности изображении (черезстрочная развертка, содержимое), на блоках 16х8 точек. Другими словами, данный блок 16х16 точек в текущем кадре ищется в соответсвующей области большего размера в предыдущих или последующих кадрах. Коэфициентны ДКП (исходных данных или разности этого блока и ему соответсвующего) квантуются, то есть делятся на некоторое число, чтобы отбросить несущественные биты. Многие коэфициенты после такой операции оказываются нулями. Коэфициент квантизации может изменяться для каждого "макроблока" (макроблок - блок 16х16 точек из Y-компонент и соответсвующие блоки 8х8 в случае отношения YUV 4:2:0, 16х8 в случае 4:2:2 и 16х16 в случае 4:4:4. Коэфициенты ДКП, параметры квантизации, векторы движения и пр. кодируется по Хаффману с использованием фиксированных таблиц, определенных стандартом. Закодированные данные складываются в пакеты, которые формируют поток согласно синтаксису MPEG.
из которых формируются предсказания) показаны
Иллюстрация 4

Исходные кадры - reference - ( из которых формируются предсказания) показаны безотносительно своей закодированной формы. Как только кадр раскодирован, он становится не набором блоков, а обычным плоским цифровым изображением из точек.
Пропущенные макроблоки
Иллюстрация 8

Пропущенные макроблоки в P-фреймах:
Пропущенные макроблоки
Иллюстрация 9
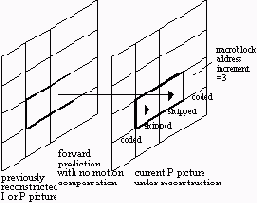
Пропущенные макроблоки в B-фреймах:
к высокочастотным составляющим: скалярное квантование
Иллюстрация 11

Особенности человеческого зрения - невосприимчивость к высокочастотным составляющим: скалярное квантование коэфициентов ДКП с потерей качества.
в целом: предсказание первого низкочастотного
Иллюстрация 12

Большая пространственная корреляция изображения в целом: предсказание первого низкочастотного коэфициента преобразования в блоке 8х8 (среднее значение всего блока).
Статистика появления синтаксических элементов в наиболее вероятном кодируемом потоке: оптимальное кодирование векторов движения, коэфициентов ДКП, типов макроблоков и пр.
Разряженная матрица квантованных коэфициентов ДКП: кодирование повторяющихся нулевых элементов с обозначением конца блока.
Пространственное маскирование: степень квантования макроблока.
Кодирование участков с учетом содержания сцены: степень квантования макроблока.
Адаптация к локальным характеристикам изображения: кодирование блоков, тип макроблока, адаптивное квантование.
Постоянный размер шага при адаптивном квантовании: новая степень квантования устанавливается только специальным тпом макроблока и не передается по умолчанию.
Временная избыточность: прямые и обратные векторы движения на уровне макроблоков 16х16 точек.
Кодирование ошибки предсказаний макроблоков с учетом восприятия: адаптивное квантование и квантование коэфициентов преобразования.
Малая ошибка предсказания: для макроблока может быть сигнализировано отсутвие ошибки.
Тонкое кодирование ошибки предсказания на уровне макроблоков: каждый из блоков внутри макроблока может быть кодирован или пропущен.
Векторы движения - медленное движение фрагмента изображения со сложным рисунком: предсказание векторов движения.
Появления и исчезновения: прямое и обратное предсказание в B-фреймах.
Точность межкадрового предсказания: билинейно интерполированные (фильтрованные) разности блоков. В реальном мире движения объектов от кадра к кадру редко попадают на границы точек. Интерполяция позволяет выяснить настоящее положение объекта, зачастую увеличивая эффективность сжатия на 1 дБ.
пропущенные макроблоки. Когда вектор движения
Иллюстрация 13

Ограниченная активность движения в P-фреймах: пропущенные макроблоки. Когда вектор движения и ошибка предсказания нулевые. Пропущенные макроблоки очень желательны в кодированном потоке, поскольку не занимают битов, кроме как в заголовке следующего макроблока.
Компланарное движение в B-фреймах: пропущенные макроблоки. Когда вектор движения тот же, а ошибка предсказания нулевая.
Имеет ли он отношение к JPEG?
Имеет ли он отношение к JPEG?
Да, названия созвучны, и группы принадлежат одному подкомитету ISO, вместе с JBIG и MHEG, и встречаются они в одно время и в одном месте. Тем не менее, это разные люди с разными целями и запросами. JPEG предназначен для сжатия неподвижных изображений, а MPEG - "живого" видео и сопутствующего аудио.
Как достигается сжатие аудио?
Как достигается сжатие аудио?
Сердце всей схемы сжатия - психоакустическая модель, применяемая к полосам, полученным после гребенки фильтров. На ее основе строится распределение битов. Этим моделям посвящена целая область науки, познакомиться с которой можно в справочной литературе, учебнике или в университете на курсе по психоакустике.
Как достигается сжатие видео?
Как достигается сжатие видео?
При сжатии видео используются следующие статистические характеристики:
Пространственная корреляция: дискретное косинусное преобразование 8х8 точек.
Как кадры соотносятся друг с другом?
Как кадры соотносятся друг с другом?
Существует три типа закодированных кадров. I-фремы - это кадры, закодированные как неподвижные изображения - без ссылок на последующие или предыдущие. Они используются как стартовые. P-фреймы - это кадры, предсказаные из предыдущих I- или P-кадров. Каждый макроблок в P-фрейме может идти с вектором и разностью коэфициентов ДКП от соответвующего блока последнего раскодированного I или P, или может быть закодирован как в I, если не соответсвующего блока не нашлось.
И, наконец, существуют B-фреймы, которые предсказаны из двух ближайших I или P-фреймов, одного предыдущего и другого - последующего. Соответсвующие блоки ищутся в этих кадрах и из них выбирается лучший. Ищется прямой вектор, затем обратный и вычисляется среднее между соответсвующими макроблоками в прошлом и будущем. Если это не работает, то блок может быть закодирован как в I-фрейме.
Последовательность раскодированных кадров обычно выглядит как
I B B P B B P B B P B B I B B P B B P B ...
Здесь 12 кадров от I до I фрейма. Это основано на требовании произвольного доступа, согласно которому начальная точка должна повторяться каждые 0.4 секунды. Соотношение P и B основано на опыте.
Чтобы декодер мог работать, необходимо, чтобы первый P-фрейм в потоке встретился до первого B, поэтому сжатый поток выгдядит так:
0 x x 3 1 2 6 4 5 ...
где числа - это номера кадров. xx может не быть ничем, если это начало последовательности, или B-фреймы -2 и -1, если это фрагмент из середины потока.
Сначала необходимо раскодировать I-фрейм, затем P, затем, имея их оба в памяти, раскодировать B. Во время декодирования P показывается I-фрейм, B показываются сразу, а раскодированный P показывается во время декодирования следующего.
Как работает MPEG аудио?
Как работает MPEG аудио?
MPEG стандарт определяет три высокопроизводительных схемы сжатия звука, называемых уровнями: Layer 1, 2 и 3. С возрастанием номера возрастает сложность и производительность алгоритма кодирования, задержка кодирования и соотношение качества восстановленного сигнала к величине потока. Эти три схемы иерархически совместимы, то есть декодер уровня 3 может читать уровни 3, 2 и 1, а декодер уровня 2 - 2 и 1. Для каждого уровня стандарт жестко определяет синтаксис потока и алгоритм декодирования.
Все уровни имеют одинаковую базовую структуру. Кодер анализирует входной сигнал, вычисляя для него гребенку фильтров, и применяет к нему психоакустическую модель. На стадии квантования и кодирования кодер пытается так распределить доступные биты данных, чтобы выполнить требования фиксированной, наперед заданной величины потока и маскирования.
Декодер менее сложен. Его задача - синтезировать звуковой сигнал из спектральных компонент.
Все три уровня используют одну гребенку фильтров (32 полосы). Помимо этого, Уровень 3 применяет модифицированное дискретное косинусное преобразование (МДКП), чтобы увеличить частотную характеристику. Все уровни используют одну структуру потока и одни информационные заголовки, для поддержания иерархической совместимости. Частота оцифровки входного сигнала может быть 32, 44.1 и 48 КГц.
| Уровень | Минимальный поток, Кбит/с | Максимальный поток, Кбит/с | Минимальная теоретическая задержка кодера, мс |
| 1 | 32 | 448 | 19 (<50) |
| 2 | 32 | 384 | 35 (100) |
| 3 | 32 | 320 | 59 (150) |
В скобках - приблизительная величина реальной задержки.
Как работает MPEG видео?
Как работает MPEG видео?
Цветное цифровое изображение из сжимаемой последовательности переводится в цветовое пространство YUV (YCbCr). Компонента Y представляет собой интенсивнось, а U и V - цветность. Так как человеческий глаз менее восприимчив к цветности, чем к интенсивности, то разрешений цветовых компонент может быть уменьшено в 2 раза по вертикали, или и по вертикали и по горизонтали. К анимации и высококачественному студийному видео уменьшение разрешения не применяется для сохранения качества, а для бытового применения, где потоки более низкие, а аппаратура более дешевая, такое действие не приводит к заметным потерям в визуальном восприятии, сохраняя в то же время драгоценные биты данных.
Как сжимается аудио?
Как сжимается аудио?
При сжатии аудио используются хорошо разработанные психоакустические модели, полученные из экспериментов с самыми взыскательными слушателями, чтобы выбросить звуки, которые не слышны человеческому уху. Это то, что называется "маскированием", например, большая составляющая в некоторой частоте не позволяет услышать компоненты с более низким коэфициентом в близлежащих частотах, где соотношение между энергиями частот, которае маскируются, описывается некоторой эмпирической кривой. Существуют похожие временные эффекты маскирования, а также более сложные взаимодействия, когда временной эффект может выделить частоту или наоборот.
Звук разбивается на спектральные блоки с помощью гибридной схемы, которая объединяет синусные и полосные преобразования, и психоакустической модели, описанной на языке этих блоков. Все, что может быть убрано или сокращено, убирается и сокращается, а остаток посылается в выходной поток. В действительности, все выглядит несколько сложнее, поскольку биты должны распределяться между полосами. И, конечно же, все, что посылается, кодируется с сокращением избыточности.
Какой уровень MPEG аудио лучше подходит для моего приложения?
Какой уровень MPEG аудио лучше подходит для моего приложения?
1. Коэфициет сжатия свыше 100:1
Зачастую статьи в прессе и маркетинговой литературе заявляют, что MPEG достигает необычайно высокого качества видео при степени сжатия свыше 100:1. Эти заявления обычно не включают понижение цветового разрешения исходного цифрового изображения. На практике, поток кодируемого изображения редко превышает величину потока, закодированного в MPEG, более чем в 30 раз. Предварительное сжатие за счет уменьшения цветового разрешения играет основную роль в формировании коэфициетнов сжатия с 3 нулями во всех методах кодирования видео, включая отличные от MPEG.
Компенсация движения заменяет макроблоки макроблоками из предыдущих картинок
3. Компенсация движения заменяет макроблоки макроблоками из предыдущих картинок
Предсказания макроблоков формируются из соответсвующих 16х16 блоков точек (16х8 в MPEG-2) из предыдущих восстановленных кадров. Никаких ограничений на положение макроблока в предыдущей картинке, кроме ее границ, не существует.
2. MPEG-1 всегда 352x240
Как MPEG-1, так и MPEG-2, могут быть применены к широкому классу потоков, частот и размеров кадров. MPEG-1, знакомый большинству людей, позволяет передавать 25 кадров/с с разрешением 352x288 в PAL или 30 кадр/с с разрешением 352x240 в NTSC при величине потока менее 1.86 Мбит/с - комбинация, известная как "Constrained Parameters Bitstreams". Это цифры введены спецификацией White Book для видео на CD ().
Фактически, синтаксис позволяет кодировать изображения с разрешением до 4095х4095 с потоком до 100 Мбит/с. Эти числа могли бы быть и бесконечными, если бы не ограничение на количество бит в заголовках.
С появлением спецификации MPEG-2, самые популярные комбинации были объединены в уровни и профили. Самые общие из них:
Source Input Format (SIF), 352 точки x 240 линий x 30 кадр/с, известный также как Low Level (LL) - нижний уровень,
и
"CCIR 601" (например 720 точек/линию x 480 линий x 30 кадр/с), илиMain Level - основной уровень.
Не забудем о частоте кадров.
6. Не забудем о частоте кадров.
Большинство коммерческих видеофильмов снимаются с киноленты, а не с видео. Основная часть фильмов, записанных на компакт-диски, была оцифрована и редактирована при 24 кадр/с. В такой последовательности 6 из 30 кадров, отображаемых на телевизионном мониторе (30 кадр/с или 60 полей/с а NTSC), фактически избыточна, и может быть не кодирована в MPEG поток. Это ведет нас к шокирующему выводу, что действительный поток был всего 24 Мбит/с (24 кадр/с / 30 кадр/с * 30 Мбит/с), и коэфициент сжатия составляет всего каких-то 21:1.
Даже при таком скромном коэфициенте сжатия, как 20:1, несоответсвия могут возникнуть между исходной последовательность изображений и восстановленной. Только консервативные коэфициенты в районе 12:1 и 8:1 демонстрируют почти полную прозрачность процесса сжатия последовательностей с сложными пространственно-временными характеристиками (резкие движения, сложные текстуры, резкие контуры и т.д.). Несмотря на это, правильно закодированное видео с использованием предварительной обработки и грамотного распределения битов, может достигать и более высоких коэфициентов сжатия при приемлемом качестве восстановленного изображения.
Откуда берутся огромные коэфициенты сжатия?
Откуда берутся огромные коэфициенты сжатия?
Коэфициетн сжатия MPEG видео часто заявляется как 100:1, тогда как в действительности он находися в районе от 8:1 до 30:1.
Как получается "более 100:1" для видео на компакт-диске (White Book) с потоком 1.15 Мбит/с.
Размер отображаемой картинки совпадает с размером закодированной
4. размер отображаемой картинки совпадает с размером закодированной
В MPEG размеры отображаемой картинки и частота кадров может отличаться от закодированного в потоке. Например, перед кодированием некотрое подмножество кадров в исходной последовательности может быть опущено, а затем каждый кадр фильтруется и обрабатывается. При восстановлении интерполированы для восстановления исходного размера и частоты кадров.
Фактически, три фундаментальных фазы (исходная частота, кодированная и показываемая) могут отличаться в параметрах. Синтаксис MPEG описывает кодированную и показываемую частоту через заголовки, а исходная частота кадров и размер известен только кодеру. Именно поэтому в заголовки MPEG-2 введены элементы, описывающие размер экрана для показа видеоряда.
Странные слухи об MPEG.
Странные слухи об MPEG.
По прчине новизны, существует множество, зачастую непонятных и надуманных, неправдоподобных слухов об MPEG. Как то:
Структура последовательности строго фиксирована шаблоном I,P,B.
6. Структура последовательности строго фиксирована шаблоном I,P,B.
Последовательнось кадров может иметь любую структуру размещения I, P и B фреймов. В промышленной практике принято иметь фиксированную последовательность (вроде IBBPBBPBBPBBPBB), однако, более мощные кодеры могут оптимизировать выбор типа кадра в зависимости от контекста и глобальных характеристик видеоряда.
Каждый тип кадра имеет свои преимузества в зависимости от особенностей изображения (активность движения, временные эффекты маскирования,...). Например, если последовательность изображений мало меняется от кадра к кадру, есть смысл кодировать больше B-фреймов, чем P. Поскольку B-фреймы не используются в дальнейшем процессе декодирования, они могут быть сжаты сильнее, без влияния на качество видеоряда в целом.
Требования конкретного приложения также влияют на выбор типа кадров: ключевые кадры, переключение каналов, индексирование программ, восстановление от ошибок и т.д.
Учтем более высокое разрешение цветности.
4. Учтем более высокое разрешение цветности.
Известный студийный сигнал CCIR-601 представляет сигнал цветности с половинным разрешением по горизонтали, но с полным вертикальным разрешением. Это соотношение частот оцифровки известно как 4:2:2. Однако, MPEG-1 и MPEG-2 Main Profile устанавливают использование формата 4:2:0, который считается достаточным для бытовых приложений. В этом формате разрешение цветоразностных сигналов в 2 раза меньше по горизонтали и вертикали, чем интенсивность. Таки образом, имеем:
720 точек x 480 линий x 30 кадр/с x 8 бит/отсчет x 1.5 остчетов/точку = 124 Мбит/с
...и отношение уже становится 108:1.
Учтем большее количество бит/точку.
3. Учтем большее количество бит/точку.
В MPEG на точку отводится 8 бит. Принимая во внимание этот фактор, отношение становится 180 * (8/10) = 144:1.
Учтем размер кодируемого изображения.
5. Учтем размер кодируемого изображения.
Последняя стадия предварительной обработки - это преобразование кадра формата CCIR-601 в формат SIF уменьшением в 2 раза по горизонтали и вертикали. Всего в 4 раза. Качественное масштабирование по горизонтали выполняется с помощью взвешенного цифрового фильтра с 7 или 4-мя узлами, а по вертикали - выбрасыванием каждого второй линии, второго поля или, опять, цифровым фильтром, управляемым алгоритмом оценки движения между полями. Отношение теперь становится
352 точек x 240 линий x 30 кадр/с x 8 бит/отсчет x 1.5 отсчетов/точку ~= 30 Мбит/с !!
... 26:1.
Таким образом, нстоящее отношение A/B должно вычисляться между исходной последовательностью в стадии 30 Мбит/с перед кодированием, поскольку это есть действительная частота оцифровки, записываемая в заголовках потока и воспроизводимая при декодировании. Так, сжатия можно добиться уже одним сокращением частоты оцифровки.
нацелен на величину выходного потока
Уровень 1
нацелен на величину выходного потока 192 Кбит/с на канал. Это упрощенная версия Уровня 2. Лучше всего он подходит для больших величин потока в районе 192 Кбит/с. Разновидность Уровня 1 используется в устройствах записи цифровых компакт-кассет (DCC, PASC).
Уровень 2
предназначен для потоков 128 Кбит/ с на канал. Он идентичен MUSICAM, и был разработан как "золотая середина" между качеством звука к величине потока и сложностью кодера. Лучше всего подходит для средних величин потока в районе 128 или даже 96 Кбит/с на канал. Уровень 2 было решено успользовать DAB (EU 147) для Цифровой Радиовещательной Сети (Digital Audio Broadcasting network).
Уровень 3
предназначается для потоков 64 Кбит/ с на канал. Он объединяет в себе лучшее из MUSICAM и ASPEC, и был разработан специально для низких величин потока в районе 64 Кбит/с и ниже. Формат Уровня 3 определяет ряд усовершенствованных методик, служащих для одной цели - сохранить максимальное качество звука даже при низком потоке. Сегодня Уровень 3 используется в различных сетях связи (ISDN, спутниковые каналы) и системах анализа речи.
В I, P и B-фреймах все макроблоки одного типа.
5. В I, P и B-фреймах все макроблоки одного типа.
В I-фрейме макроблоки должны быть закодированы как внутренние - без ссылок на предыдущие или последующие, если не используются масштабируемые режимы. Однако, макроблоки в P-фрейме могут быть как внутренними, так и ссылаться на предыдущие кадры. Макроблоки в B-фрейме могут быть как внутренними, так и ссылаться на предыдущий кадр, последующий или оба. В заголовке каждого макроблока есть элемент, определяющий его тип.
Выбросим гасяшие интервалы.
2. Выбросим гасяшие интервалы.
Из 858 точек яркости на линию под информацию изображения задействованы только 720. В действительности, количество точек на линию - предмет многих ссор на инженерных семинарах, и это значение лежит в пределах от 704 до 720. Аналогично, только 480 линий из 525 задействованы под изображение по вертикали. Настоящее значение лежит в пределах от 480 до 496. В целях совместимости MPEG-1 и MPEG-2 определяет эти числа как 704х480 точек на интенсивность и 352х480 для цветоразностей. Пересчитывая исходный поток, будем иметь:
| Y | 704 точек/линию x 480 линий x 30 кадр/с x 10 бит/точку ~= 104 Мбит/с |
| C | 2 компоненты x 352 точки/линию x 480 линий x 30 кадр/с x 10 бит/точку ~= 104 Мбит/с |
| Итого: | ~ 207 Мбит/с |
Отношение (207/1.15) составляет всего 180:1.
Высокое разрешение исходного видео.
1. Высокое разрешение исходного видео.
Большинство источников видеосигнала для кодирования имеют большее разрешение, чем то, которое актуально оказывается в закодированном потоке. Самый популярный студийный сигнал, известный как цифровое видео "D-1" или "CCIR 601", кодируется на 270 Мбит/с.
Цифра 270 Мбит/с получается из следующих вычислений:
| Интенсивность (Y): | 858 точек/линию x 525 линий/кадр x 30 кадр/с x 10 бит/точку ~= 135 Мбит/с |
| R-Y (Cb): | 429 точек/линию x 525 линий/кадр x 30 кадр/с x 10 бит/точку ~= 68 Мбит/с |
| B-Y (Cb): | 429 точек/линию x 525 линий/кадр x 30 кадр/с x 10 бит/точку ~= 68 Мбит/с |
| Итого: | 27 млн. точек/с x 10 бит/точку = 270 Мбит/с |
Итак, начинаем с коэфициента сжатия 270/1.15... 235:1!!!!!